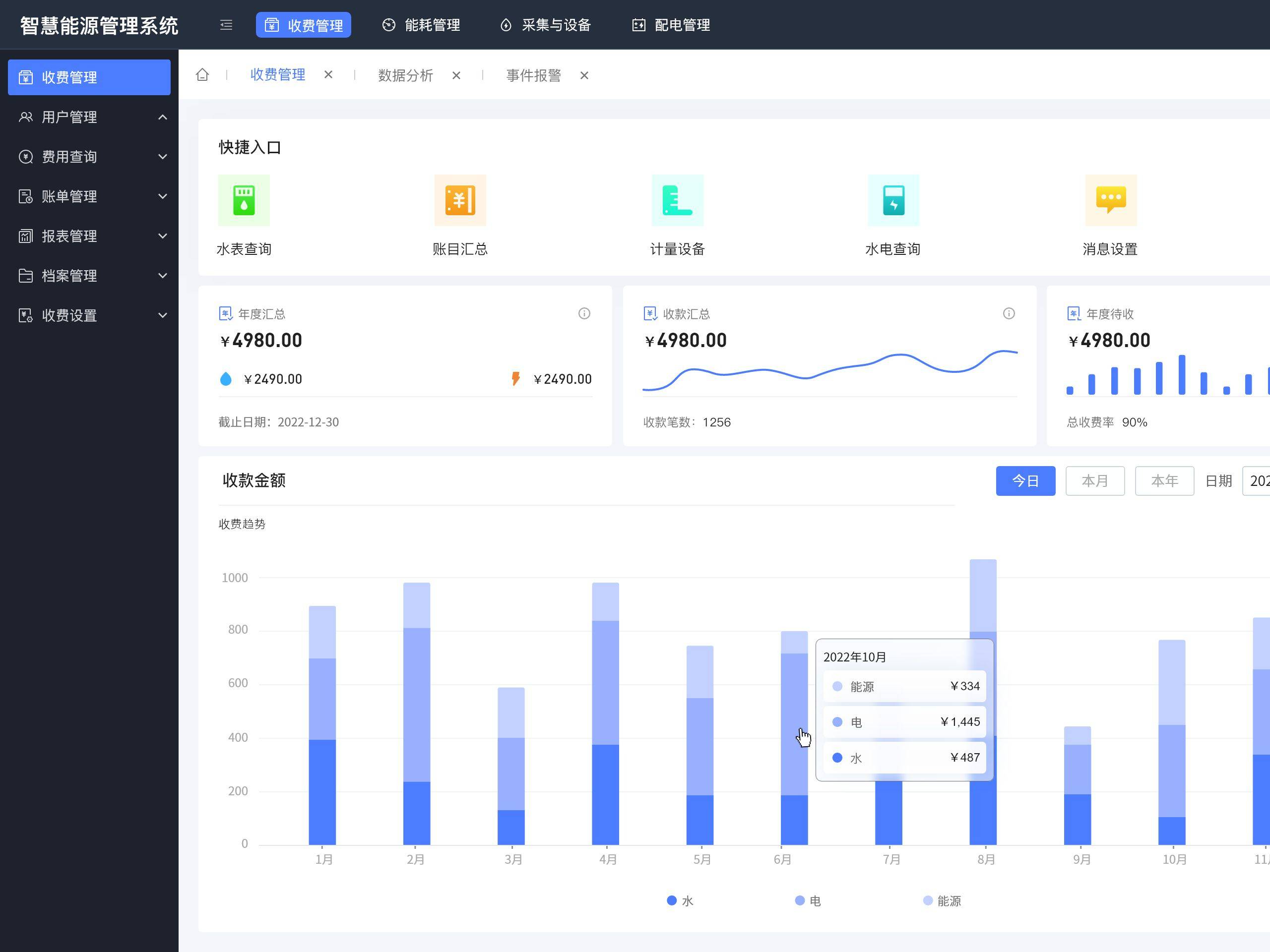
分布式系統(tǒng)中的容錯(cuò)形成區(qū)塊鏈
時(shí)間:2019-02-20 12:07:18 閱讀:98417次
分類(lèi):行業(yè)新聞
分布式系統(tǒng)是實(shí)現(xiàn)高可伸縮性,局部性和可用性的基本概念。但是,另一方面,從客戶端查看時(shí),整個(gè)系統(tǒng)需要很多原創(chuàng)才能看起來(lái)一致。另外,據(jù)說(shuō)構(gòu)建具有完整功能的分布式系統(tǒng)幾乎是不可能的,并且有必要選擇應(yīng)用程序應(yīng)...
分布式系統(tǒng)是實(shí)現(xiàn)高可伸縮性,局部性和可用性的基本概念。但是,另一方面,從客戶端查看時(shí),整個(gè)系統(tǒng)需要很多原創(chuàng)才能看起來(lái)一致。另外,據(jù)說(shuō)構(gòu)建具有完整功能的分布式系統(tǒng)幾乎是不可能的,并且有必要選擇應(yīng)用程序應(yīng)該強(qiáng)調(diào)哪些屬性。
除了描述這些分布式系統(tǒng)的特性外,我們還描述了具有高性能的區(qū)塊鏈的特征。最后,通過(guò)總結(jié)容錯(cuò)屬性,我們將進(jìn)一步探索區(qū)塊鏈的更大潛力,并希望通過(guò)討論每個(gè)高級(jí)區(qū)塊鏈項(xiàng)目(如Tendermint)來(lái)充分解釋MOLD應(yīng)該瞄準(zhǔn)的系統(tǒng)。
1.簡(jiǎn)介(容錯(cuò)概述和整體流程)
與單個(gè)系統(tǒng)不同,分布式系統(tǒng)存在部分故障。單個(gè)系統(tǒng)的整體故障通常會(huì)導(dǎo)致整個(gè)系統(tǒng)崩潰。另一方面,在部分故障中,系統(tǒng)可以在從部分故障恢復(fù)的同時(shí)繼續(xù)運(yùn)行而不會(huì)嚴(yán)重影響整體性能。
在本文中,我們將按以下順序解釋容錯(cuò);即使系統(tǒng)的一部分發(fā)生故障,系統(tǒng)也可以繼續(xù)處理。
·什么樣的屬性是容錯(cuò)的
·什么樣的失敗以及如何歸類(lèi)
如何在分布式系統(tǒng)中實(shí)現(xiàn)容錯(cuò)
·關(guān)于溝通失敗
·“可靠的多播”增加了過(guò)程的阻力
·關(guān)于分布式提交問(wèn)題
2.什么是容錯(cuò)?
容錯(cuò)
容錯(cuò)定義如下
即使發(fā)生故障也能忍受服務(wù)
此外,具有容錯(cuò)性的系統(tǒng)有時(shí)被稱(chēng)為高可靠性系統(tǒng),并且與可靠性系統(tǒng)相關(guān)的要求分為以下四種。
中的容錯(cuò)形成區(qū)塊鏈")
失敗模型
分布式系統(tǒng)中進(jìn)程的典型故障如下:
中的容錯(cuò)形成區(qū)塊鏈")
通信鏈路的故障也被分類(lèi)。
中的容錯(cuò)形成區(qū)塊鏈")
例如,對(duì)于分布式故障,可能會(huì)發(fā)生虛假消息的傳遞,因此最難處理。
冗余可以隱藏故障。這很容易理解,例如考慮到哺乳動(dòng)物有兩只眼睛,耳朵和肺部。即使這些分布式器官中的一些失效,您也可以在隱藏故障的同時(shí)使用該系統(tǒng)。這稱(chēng)為物理冗余。冗余有三種類(lèi)型:信息冗余,時(shí)間冗余和物理冗余。
3.流程靈活性
在描述容錯(cuò)之后,我們考慮如何實(shí)現(xiàn)容錯(cuò)。
流程復(fù)制
典型的方法是進(jìn)程復(fù)制。在組中創(chuàng)建(復(fù)制)相同的進(jìn)程稱(chēng)為復(fù)制。通過(guò)在分布式系統(tǒng)中復(fù)制,即使在部分故障的情況下,也可以通過(guò)正常過(guò)程提供服務(wù)。我們將復(fù)制過(guò)程稱(chēng)為副本。
有兩種方法可以重用(復(fù)制)。
·主要基礎(chǔ)協(xié)議(被動(dòng)副本)
·重復(fù)寫(xiě)協(xié)議(PositiveReplication)
在前者中,只有主副本處理來(lái)自客戶端的消息,而另一個(gè)副本備份主進(jìn)程。盡管復(fù)制品之間的處理結(jié)果不一致并且更容易實(shí)現(xiàn)通信功能,但是主復(fù)制品的故障需要選擇算法,并且處理有些復(fù)雜。
在后一種情況下,所有副本都從客戶端接收和處理消息。此時(shí),基于消息的處理需要總排序和原子性?xún)蓚€(gè)屬性。因此,原子多播需要更復(fù)雜的通信功能。
中的容錯(cuò)形成區(qū)塊鏈")
kFault容忍度
在重復(fù)寫(xiě)入?yún)f(xié)議中,據(jù)說(shuō)存在k個(gè)容錯(cuò),即使它們失敗,k個(gè)分量也可以正常移動(dòng)。如果您有分布式故障,則至少需要2k + 1個(gè)進(jìn)程才能具有k容錯(cuò)能力。
原子多播問(wèn)題
作為上述復(fù)制模型的前提,存在所有請(qǐng)求必須以相同順序到達(dá)所有服務(wù)器的條件。這稱(chēng)為原子多播問(wèn)題。這將在第5章中詳細(xì)討論。
流程之間的協(xié)議
進(jìn)程之間的協(xié)議問(wèn)題對(duì)于為分布式系統(tǒng)提供容錯(cuò)至關(guān)重要。分布式協(xié)議算法的目的是在有限數(shù)量的步驟中達(dá)成共識(shí)以實(shí)現(xiàn)彼此之間不會(huì)失敗的過(guò)程,并且在代表性過(guò)程中存在一般分布式問(wèn)題。
分布式一般問(wèn)題
在具有k個(gè)錯(cuò)誤過(guò)程的系統(tǒng)中,僅當(dāng)存在2k + 1個(gè)或更多個(gè)正常過(guò)程并且整體上存在N=< 3k + 1個(gè)過(guò)程時(shí)才達(dá)到協(xié)議。換句話說(shuō),只有超過(guò)三分之二的流程能夠正常運(yùn)作才能達(dá)成協(xié)議。 (如果小于此值,則可能因過(guò)程失敗而受騙。)
附錄:容錯(cuò)所需的正常節(jié)點(diǎn)數(shù)
對(duì)于許多協(xié)議,具有分布式阻塞的最大允許節(jié)點(diǎn)數(shù)稱(chēng)為1/3。原因?qū)⒃谙旅婧?jiǎn)要描述。
設(shè)“N”為節(jié)點(diǎn)總數(shù),“F”為分布式節(jié)點(diǎn),“T”為正常共識(shí)所需的節(jié)點(diǎn)數(shù)。
例如,假設(shè)“N-F”的正常節(jié)點(diǎn)被分成相同的數(shù)字,并且數(shù)字如下。
(N-F)/2
由于“F”的分布式節(jié)點(diǎn)具有任意行為,為了正常達(dá)成共識(shí),必須滿足以下表達(dá)式。
T> (N-F)/2 + F···1
另外,考慮到F的所有分布式節(jié)點(diǎn)都是離線的,其他正常節(jié)點(diǎn)可以采用一致性,因此以下表達(dá)式成立。
N-F≥T···2
從1·2,
N-F> (N-F)/2 + F
∴F< N3
基于上述,當(dāng)總節(jié)點(diǎn)中的分布式節(jié)點(diǎn)的數(shù)量小于1/3時(shí),通常可以達(dá)到一致。
4.可靠的客戶端 - 服務(wù)器通信
到目前為止,我們已經(jīng)討論了分布式系統(tǒng)中進(jìn)程的容錯(cuò)能力并了解了復(fù)制。本章討論在通信鏈路上引入容錯(cuò)。
P2P通信
分布式系統(tǒng)中的通信基礎(chǔ)是將一個(gè)進(jìn)程連接到另一個(gè)進(jìn)程的對(duì)等通信(一對(duì)一通信)。
TCP
TCP:用于可靠通信的點(diǎn)對(duì)點(diǎn)通信
TCP具有序列號(hào),定時(shí)器,校驗(yàn)和,確認(rèn),重傳控制,擁塞控制等機(jī)制。例如,可以通過(guò)包括TCP序列號(hào)和基于確認(rèn)的重傳控制的確認(rèn)來(lái)處理由于丟失消息而導(dǎo)致的遺漏失敗。
失敗時(shí)的RPC(遠(yuǎn)程過(guò)程調(diào)用)
RPC的目的是以本地過(guò)程調(diào)用的形式實(shí)現(xiàn)進(jìn)程間通信,而無(wú)需了解通信部分。在使用RPC的分布式系統(tǒng)中可能會(huì)發(fā)生五個(gè)障礙。
1.客戶端找不到服務(wù)器。
2.從客戶端到服務(wù)器的請(qǐng)求消息將丟失。
3.服務(wù)器收到請(qǐng)求后崩潰。
4.從服務(wù)器到客戶端的響應(yīng)消息將丟失。
5.客戶端發(fā)送請(qǐng)求消息后發(fā)生故障。
作為針對(duì)每個(gè)的對(duì)策,存在設(shè)置異常處理和計(jì)時(shí)器(時(shí)間限制)的方法。
5.可靠的團(tuán)隊(duì)溝通
我們?cè)谇耙徽轮攸c(diǎn)介紹了一對(duì)一通信,因此我們?cè)诖私忉屢粚?duì)多組播通信的高可靠性。在分布式系統(tǒng)中,重要的是在不泄漏的情況下發(fā)送消息,包括向彼此的服務(wù)器發(fā)送訂單。
可靠的組播無(wú)故障
考慮按順序向每個(gè)成員發(fā)送消息。
發(fā)送方首先將多播消息保存在手頭的歷史存儲(chǔ)器中。此外,發(fā)送方從接收方接收傳輸確認(rèn)通知(A高仿CK)。在A高仿CK中,最后一個(gè)消息標(biāo)識(shí)符的輸入和返回已完成。如果由于消息丟失等原因而無(wú)法接收包含預(yù)期標(biāo)識(shí)符的A高仿CK,則發(fā)送方重新發(fā)送該消息。
確保來(lái)自發(fā)件人的郵件以相同的順序傳遞到所有進(jìn)程。
在分布式系統(tǒng)中,不是“過(guò)程”
具有“何時(shí)”發(fā)送方“在發(fā)送期間失敗,傳遞給所有剩余進(jìn)程或被忽略”的屬性的可靠多播稱(chēng)為虛擬同步。
此外,虛擬同步并以整體順序執(zhí)行消息傳遞的通信稱(chēng)為原子多播。
Isis實(shí)現(xiàn)虛擬同步的一個(gè)例子。 Isis保留并轉(zhuǎn)移mmessageM進(jìn)行處理,直到它知道所有成員都收到了消息M.
6.分發(fā)提交
促進(jìn)原子多播問(wèn)題的問(wèn)題稱(chēng)為分布式提交。
中的容錯(cuò)形成區(qū)塊鏈")
原子提交
有必要在最后判斷是否始終提交或暫停不同類(lèi)似網(wǎng)站的流程。這種類(lèi)型的操作稱(chēng)為原子提交。
6-1。兩階段提交協(xié)議(2PC)
兩階段提交協(xié)議(2PC)是實(shí)現(xiàn)原子提交的典型方法。顧名思義,每個(gè)階段包括兩個(gè)步驟,組織如下。
(第1階段[投票階段])
組織者向所有參與者發(fā)送VOTE_REQUEST消息
2.收到VOTE_REQUEST消息的參與者如果能夠提交交易并通過(guò)發(fā)送VOTE_ABORT消息進(jìn)行投票(如果需要中止),則會(huì)向組織者發(fā)送VOTE_COMMT消息。
(第2階段[提交階段])
3.主辦方收集所有參與者的投票。如果所有投票都是COMMIT,我們承諾并向所有參與者發(fā)送GLOBAL_COMMIT消息。如果有多個(gè)ABORT,它決定中止事務(wù)并發(fā)送GLOBAL_ABORT消息。
4.參與者等待來(lái)自組織者的消息,如果它是GLOBAL_COMMIT本地則提交,如果是GLOBAL_ABORT則丟棄該事務(wù)。
在整個(gè)過(guò)程中,組織者和參與者執(zhí)行以下?tīng)顟B(tài)轉(zhuǎn)換。
中的容錯(cuò)形成區(qū)塊鏈")
阻止提交協(xié)議
上述兩階段提交協(xié)議存在很大問(wèn)題。當(dāng)組織者在第3階段失敗并且所有參與者都在等待來(lái)自組織者的消息時(shí)。參與者不能合作確定最終應(yīng)采取的行動(dòng)決定。因此,兩階段提交被稱(chēng)為阻止提交協(xié)議。
事實(shí)上,在兩階段提交中很少發(fā)生阻塞,因此它沒(méi)有被大量使用,但是三階段提交協(xié)議被設(shè)計(jì)為避免阻塞的解決方案。
6-2。三階段提交
與兩階段提交協(xié)議不同,三階段提交協(xié)議滿足以下兩個(gè)條件。 [Skeen和Stonebraker,1983]指出這兩個(gè)條件對(duì)于非阻塞提交協(xié)議是必要和充分的。
1.沒(méi)有直接訪問(wèn)COMMIT狀態(tài)或ABORT狀態(tài)。
2.無(wú)法做出最終決定或過(guò)渡到COMMIT狀態(tài)。
SKEEN,D.andSTONEBRAKER,M“AFormalModelofCrashRecoveryinaDistributedSystem。” IEEE Trans.Softw.Eng。,1983年3月
具體地,PRECOMMIT狀態(tài)在兩階段提交的兩個(gè)階段之間提供。
整個(gè)參與者和組織者改變了狀態(tài)如下。
中的容錯(cuò)形成區(qū)塊鏈")
兩階段提交之間的最大區(qū)別是所有進(jìn)程都返回INIT,ABORT和PRECOMMIT狀態(tài)。由于它永遠(yuǎn)不會(huì)處于READY狀態(tài),因此剩余的進(jìn)程總是做出最終決定,并且可以充當(dāng)非阻塞協(xié)議。
三階段提交只是一個(gè)概念表示,即使組織者失敗,也沒(méi)有正常工作的機(jī)制。然而,在區(qū)塊鏈出現(xiàn)后,其歷史將發(fā)生很大變化。 Tendermint項(xiàng)目通過(guò)在區(qū)塊鏈中使用三階段提交來(lái)實(shí)現(xiàn)非阻塞協(xié)議。
7.區(qū)塊鏈中的容錯(cuò)性
最后,基于上述內(nèi)容,我們還將參考分布式區(qū)塊鏈系統(tǒng)中的容錯(cuò)。
7-1。區(qū)塊鏈容錯(cuò)
區(qū)塊鏈具有高度容錯(cuò)能力。讓我們根據(jù)第2章中分類(lèi)的四個(gè)可靠性要求,仔細(xì)研究區(qū)塊鏈的性質(zhì)。
停止運(yùn)行的區(qū)塊鏈系統(tǒng)的時(shí)間和數(shù)量很少。特別是在比特幣網(wǎng)絡(luò)中,可以說(shuō)高可用性和可靠性非常低,因?yàn)榧词鼓承┕?jié)點(diǎn)發(fā)生故障,也可以實(shí)現(xiàn)零停機(jī)并繼續(xù)正常運(yùn)行。
接下來(lái),關(guān)于安全性,當(dāng)系統(tǒng)在區(qū)塊鏈網(wǎng)絡(luò)中不能正常工作時(shí),會(huì)出現(xiàn)“事務(wù)未處理和阻塞”,“網(wǎng)絡(luò)中的信息不共享信息和分叉分區(qū)”類(lèi)問(wèn)題。后者很可能會(huì)造成重大麻煩。
關(guān)于可維護(hù)性,可以說(shuō)社區(qū)很容易劃分,比如像比特幣這樣的公共區(qū)塊鏈,很難從中恢復(fù)。比特幣網(wǎng)絡(luò)受到高度贊賞,因?yàn)樗鼈兙哂懈呖捎眯院涂煽啃裕虼藷o(wú)需恢復(fù),但如果您希望可維護(hù),則應(yīng)考慮選擇私有鏈或聯(lián)合鏈。
此外,區(qū)塊鏈非常有意義,因?yàn)樗鼮榉植际焦收咸峁┝擞行У慕鉀Q方案,這被認(rèn)為是最難處理的。具體而言,它是由PoW等代表的相干算法......通過(guò)形成激勵(lì)結(jié)構(gòu)來(lái)處理分布的一般問(wèn)題;礦工通過(guò)維持/貢獻(xiàn)而不是基于博弈論破壞網(wǎng)絡(luò)來(lái)獲得更多利潤(rùn)。算法。應(yīng)該指出的是,諸如硬叉之類(lèi)的新問(wèn)題正在發(fā)生,然而,可以說(shuō)它已經(jīng)取得了一些成功。另外,
Hyperledger采用的PBFT還通過(guò)設(shè)置領(lǐng)導(dǎo)節(jié)點(diǎn)來(lái)確認(rèn)投票,從而實(shí)現(xiàn)高分布式容錯(cuò)。
7-2 .Blcokchain流程的靈活性
考慮如何在容錯(cuò)描述后實(shí)現(xiàn)容錯(cuò)。
首先,有兩種方法可以處理復(fù)制。
1.主要的基礎(chǔ)協(xié)議
2.重復(fù)寫(xiě)協(xié)議
使用1的主基礎(chǔ)協(xié)議的主協(xié)議是基于PoW一致性算法的區(qū)塊鏈。在PoW的情況下,它是主基中的本地寫(xiě)協(xié)議的規(guī)范。成功找到PoW的nonce值作為獨(dú)占控件(領(lǐng)導(dǎo)者選擇算法)的礦工獲得了將塊添加為主服務(wù)器的權(quán)利。但是,當(dāng)有權(quán)成為主服務(wù)器的節(jié)點(diǎn)同時(shí)出現(xiàn)時(shí),區(qū)塊鏈將分叉。
另一方面,2的重復(fù)寫(xiě)協(xié)議是基于PBFT的區(qū)塊鏈。各種基于PBFT的共識(shí)算法(包括Tendermint)沒(méi)有主服務(wù)器首先負(fù)責(zé)執(zhí)行每個(gè)數(shù)據(jù)的更新,并且所有參與節(jié)點(diǎn)可以同時(shí)執(zhí)行寫(xiě)操作。也就是說(shuō),可以說(shuō)PBFT類(lèi)型一致性協(xié)議類(lèi)似于重復(fù)寫(xiě)入類(lèi)型的主動(dòng)拷貝協(xié)議。
7-3。區(qū)塊鏈高可靠性通信
我已經(jīng)提到了區(qū)塊鏈過(guò)程,但這次我將重點(diǎn)關(guān)注通信鏈接。
在區(qū)塊鏈中,參與網(wǎng)絡(luò)的每個(gè)節(jié)點(diǎn)執(zhí)行P2P通信并共享數(shù)據(jù)。另外,由領(lǐng)導(dǎo)者選擇算法選擇的主服務(wù)器執(zhí)行多播,例如,當(dāng)找到隨機(jī)數(shù)時(shí),將新添加的塊的信息共享給每個(gè)參與節(jié)點(diǎn)。此時(shí),考慮到在通信鏈路或節(jié)點(diǎn)中發(fā)生故障的情況,重要的是實(shí)現(xiàn)原子多播,其是虛擬同步并且以整體順序執(zhí)行消息傳遞。
那么,區(qū)塊鏈中的原子多播問(wèn)題和分布式提交問(wèn)題是如何解決的?
在像比特幣這樣的PoW公共鏈中,原子組播尚未實(shí)現(xiàn)。因此,可能會(huì)發(fā)生頻繁的貨叉。由于每個(gè)節(jié)點(diǎn)隨時(shí)間正確共享數(shù)據(jù),因此建立了一致性,但確認(rèn)事務(wù)存儲(chǔ)在塊中需要10分鐘以上。
在這里,我們應(yīng)該注意Tendermint一致性算法。通常,存在2PC(兩階段提交)作為實(shí)現(xiàn)原子提交的方法,并且已經(jīng)提出了作為改進(jìn)版本的3PC方法,但兩者都是不完整的。因此,Tendermint通過(guò)將區(qū)塊鏈與3PC方法混合并在循環(huán)方法下的節(jié)點(diǎn)上添加約束來(lái)實(shí)現(xiàn)原子提交。下一章將解釋這種創(chuàng)新的分布式提交問(wèn)題的方法。
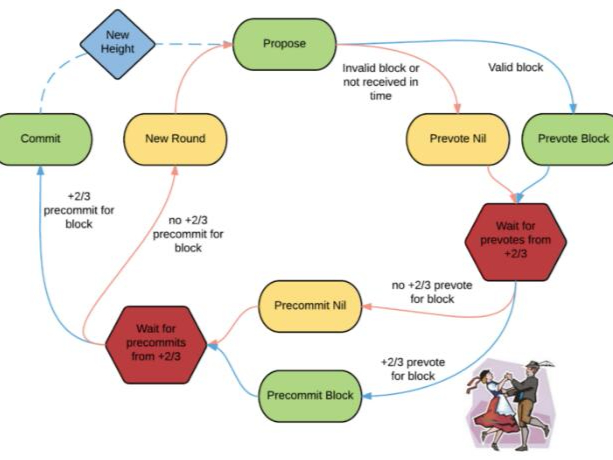
7-4。 Tendermint分布式提交(創(chuàng)新三階段提交模型)
首先,Tendermint是PBFT類(lèi)型。在Hyperledger中,作為領(lǐng)導(dǎo)者的驗(yàn)證者始終是相同的過(guò)程,但Tendermint具有領(lǐng)導(dǎo)者選擇算法,并通過(guò)循環(huán)方法確定性地確定領(lǐng)導(dǎo)者。領(lǐng)導(dǎo)者共同提出存儲(chǔ)在mempool中的下一個(gè)事務(wù)塊。通過(guò)此提議,Tendermint Consensus實(shí)施了3PC(三階段提交)并實(shí)施了原子多播。 Tendermint一致性算法可以大致分為三種狀態(tài)。
1.提議
基于基于基于領(lǐng)導(dǎo)的選擇算法基于樁數(shù)通過(guò)循環(huán)方法確定性地選擇的一組驗(yàn)證者的提議。在這種狀態(tài)下開(kāi)始投票。
2.預(yù)先投票
擬議區(qū)塊的第一次投票。一旦我們獲得三分之二或更多的批準(zhǔn),我們將繼續(xù)進(jìn)行下一步,但要等到收集所有選票的時(shí)間限制。由于這個(gè)時(shí)間限制,可以說(shuō)Tendermint是一種部分異步一致性算法。此外,投票算法具有1/3k的容錯(cuò)能力。
3.預(yù)先承諾
超過(guò)2/3的投票前同意第二次投票。此時(shí),如下所述,Tendermint的智能部分是未收集2/3或更多票數(shù)的衡量標(biāo)準(zhǔn)。
如前所述,通過(guò)為三階段提交設(shè)置PRECOMMIT階段,如果滿足以下條件,則可以實(shí)現(xiàn)阻塞協(xié)議。
1.沒(méi)有狀態(tài)直接轉(zhuǎn)換為COMMIT狀態(tài)或ABORT狀態(tài)
2.無(wú)法做出最終決定或過(guò)渡到COMMIT狀態(tài)。
在Tendermint中,在第二個(gè)投票階段投票的核查員預(yù)先提交被鎖定,并且只能在投票前投票超過(guò)鎖定塊數(shù)或塊數(shù)的2/3。通過(guò)鎖定過(guò)程,滿足上述兩個(gè)條件。換句話說(shuō),由于每個(gè)驗(yàn)證器只能在預(yù)提交中對(duì)塊進(jìn)行投票,因此它不實(shí)現(xiàn)fork機(jī)制。
換句話說(shuō),“Tendermint的共識(shí)是確保在網(wǎng)絡(luò)中的所有節(jié)點(diǎn)上完成添加塊的操作,或者根本不完成任何節(jié)點(diǎn);實(shí)現(xiàn)最終結(jié)果的下一代共識(shí)協(xié)議。
中的容錯(cuò)形成區(qū)塊鏈")
云樞智聯(lián)(海南)信息技術(shù)有限公司(原中江網(wǎng)絡(luò)),成立于2005年,經(jīng)過(guò)20多年定制開(kāi)發(fā)經(jīng)驗(yàn),積累了大量技術(shù)儲(chǔ)備和定制開(kāi)發(fā)經(jīng)驗(yàn),是一家集軟件研發(fā)、互聯(lián)網(wǎng)應(yīng)用為一體的綜合信息技術(shù)服務(wù)提供商。公司擁有核心的策劃團(tuán)隊(duì)和專(zhuān)業(yè)的技術(shù)研發(fā)團(tuán)隊(duì),致力于采用領(lǐng)先的信息技術(shù),長(zhǎng)期為涉及智慧園區(qū)/廠區(qū)/校園領(lǐng)域的各個(gè)企業(yè)提供快速、高效、安全的信息技術(shù)支持。公司立足智慧園區(qū)和智慧教育行業(yè),通過(guò)軟硬件的研發(fā)和互聯(lián)網(wǎng)應(yīng)用,疏通各企業(yè)間“端到端”的信息傳輸,靈活滿足智慧園區(qū)和智慧教育企業(yè)間不同用戶的需求,為其提供完善的信息化解決方案。